KMS 서비스 구성을 위한 스펙 및 HA 구성 절차 안내
개요
본 문서는 KMS(Key Management System) 서비스의 On-Premise 구축을 위한 스펙 및 HA(High Availability) 구성 절차를 정의하고, 안정적인 서비스 운영을 위한 고려 사항을 안내합니다. 단, KMS와 관련된 최소한의 서비스를 제외한 모든 서비스는 SaaS에 존재합니다.
하드웨어 스펙 정의
KMS만 설치하는 환경을 위한 서버당 권장 사양은 다음과 같습니다
서버당 최소 권장 사양 (세부 리소스 요구사항 포함)
- CPU : 8 Core 이상
- Kubernetes Master Role: 2 Core
- KMS: 1 Core
- ElasticSearch: 3 Core
- 여유분 20%: 약 1.2 Core
- 합계: 기본 요구사항 6 Core + 여유분 = 약 8 Core
- RAM : 32GB 이상
- Kubernetes Master Role: 4GB
- KMS: 2GB Memory
- ElasticSearch: 8GB Memory
- 여유분 20%: 약 3GB
- 합계: 기본 요구사항 14GB + 여유분 = 약 17GB (안정성을 위해 32GB 권장)
- 디스크 :
- OS 및 Docker 영역: 300GB 이상
- 데이터(Longhorn) 영역: 최소 300GB 이상
- 총 디스크 공간: 최소 600GB 이상 권장
서버당 안정적 운영을 위한 권장 사양
- CPU : 16 Core
- RAM : 64GB
- 디스크 : 600GB - 1TB
- Host OS & RKE 운영 공간: 300G (기존 200G + 폐쇄망 지원을 위한 Harbor 100G 추가)
- Longhorn Storage 용량: 300G
- ※ OS 및 RKE 운영 공간이 300G로 설정된 이유 폐쇄망 환경에서는 Harbor가 인터넷에서 컨테이너 이미지를 직접 다운로드할 수 없기 때문에, 로컬에 저장하여 서비스 재구동 시 Harbor에서 컨테이너 이미지를 불러와야 하기 때문입니다.
폐쇄망 Harbor란?
- RKE의 기본 관련 모듈, Longhorn 등을 포함한 자체 서비스 컨테이너 이미지는 원래 인터넷에서 다운로드하여 사용하는 것이 일반적입니다.
- 하지만 망분리(폐쇄망) 환경에서는 인터넷에서 직접 컨테이너 이미지를 다운로드할 수 없으므로, 서비스가 정상적으로 구동되지 못하는 문제가 발생할 수 있습니다.
- 이를 해결하기 위해 OS 영역 내에 Container Registry(Harbor)를 설치하고, 필요한 컨테이너 이미지를 사전에 저장해야 합니다.
- 이 과정에서 약 100G의 추가 저장 공간이 필요하며, 이렇게 저장된 이미지는 RKE2, Longhorn, Security365 등의 서비스에서 활용하여 정상적으로 운영될 수 있습니다.
디스크 산정 방식
- 기본 OVA 설치 및 운영 데이터 : 300GB
- Longhorn 최소 300GB × 5대 (Node 개수에 따라 증가) = 1.5TB
- Elasticsearch 데이터 저장 공간 (예상 증가분 포함) : 최소 1~2TB 이상
- 이중화 및 �확장성 고려하여 추가 여유 공간 확보 : 3TB 이상
Security365 Master OVA 이미지 사양
해당 내용은 내부 사이트에만 기술 되어있음을 안내 드립니다.
내부 사이트 링크는 하단에 첨부되어 있습니다.
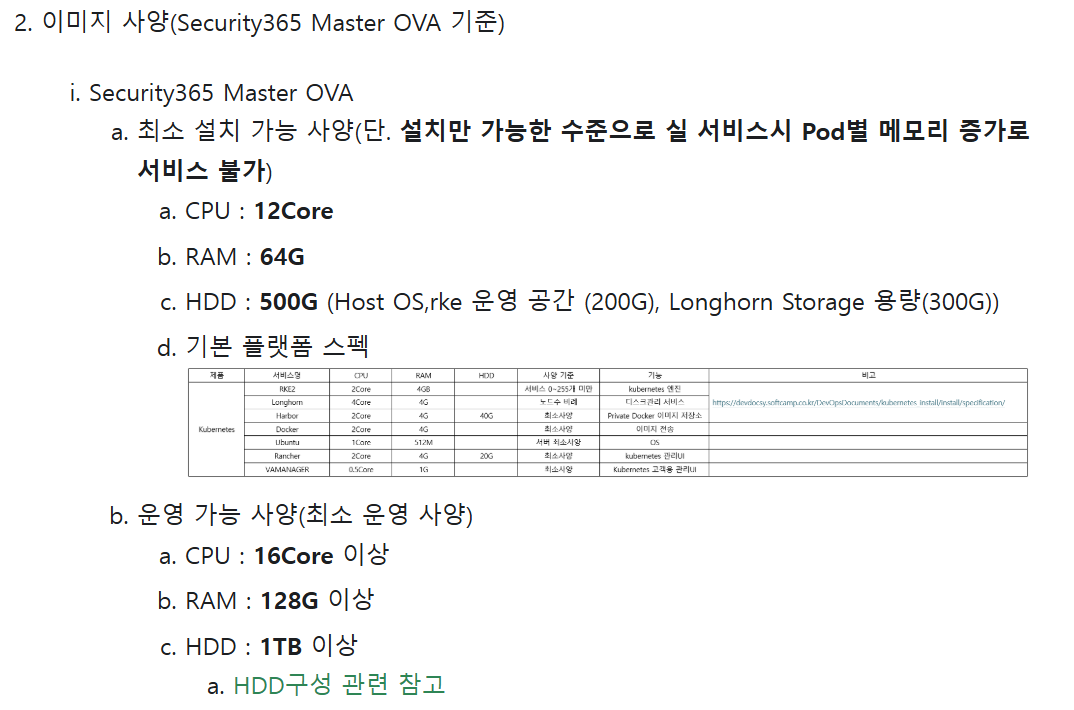
참고사항 : ElasticSearch는 데이터를 지속적으로 저장하므로, 데이터 영역은 충분히 확보하는 것이 좋습니다. 한번 제출된 스펙은 추후 증설이 불가능하고 축소만 가능하므로, 안정적인 운영을 위해 여유 있는 사양을 권장합니다.
HA 구성 절차
KMS 서비스 HA 구성을 위한 절차는 다음과 같습니다:
- Master OVA 1대 구성
- 기본 Master 노드 설치
- IP/도메인 변경
- 환경에 맞게 IP 및 도메인 설정
- KMS 관련 서비스만 활성화
- 그 외 서비스는 비활성화 처리
- Slave OVA 4대 구성
- 각 서버마다 IP 변경 필요하며 Master 노드 설치
- Node Join 작업
- 4대 모두 ControlPlane 역할 수행으로 Join
kubectl join --control-plane명령어 사용
- Longhorn 볼륨 Replicas 조정
- 1 → 5로 조정
kubectl -n longhorn-system edit volume [볼륨명]명령으로numberOfReplicas: 5설정
- Elasticsearch Replicas 조정
- 1 → 5로 Scale 조정
kubectl -n logging scale statefulset elasticsearch-master --replicas=5
- Cloud 서비스 URL 변경 요청
- KMS 서비스 URL 변경을 위해 Cloud연구부에 요청
구성 점검을 위한 체크리스트
Master 노드 점검
-
kubectl get nodes명령어로 모든 노드가 Ready 상태인지 확인 -
kubectl get pods -A명령어로 모든 Pod가 Running 상태인지 확인
KMS 서비스 점검
-
kubectl -n kms get pods명령어로 KMS 관련 Pod가 정상 실행 중�인지 확인 -
kubectl -n kms get svc명령어로 서비스 엔드포인트 확인
스토리지 및 로깅 점검
-
kubectl -n longhorn-system get pods명령어로 Longhorn 상태 확인 -
kubectl -n longhorn-system get volume명령어로 볼륨 Replica 설정 확인 -
kubectl -n logging get pods명령어로 ElasticSearch 상태 확인
고가용성 테스트
- 임의의 노드 1대 중단 후 서비스 정상 작동 확인
- 부하 테스트를 통한 성능 및 안정성 확인
이중화 및 장애 대응 상세 안내
이중화 구성 요구사항
- 최소 노드 수 : Master Role 장비 3대 이상 (5대 구성 권장)
- 복제본 설정 :
- KMS Replicas: Master Role 개수와 동일하게 설정 (5대 구성 시 5개)
- ElasticSearch Replicas: Master Role 개수와 동일하게 설정 (5대 구성 시 5개)
- Longhorn Replicas: Master Role 개수와 동일하게 설정 (5대 구성 시 5개)
장애 시나리오 및 대응 방안
- 1대 장애 시 : 서비스 정상 작동 (4/5 노드 가동, 과반수 이상 유지)
- 2대 장애 시 : 서비스 정상 작동 (3/5 노드 가동, 과반수 이상 유지)
- 3대 이상 장애 시 : 서비스 불안정 또는 중단 가능성 높음 (과반수 미만으로 etcd 쿼럼 손실)
중요 : etcd는 과반수 이상의 노드가 정상 작동해야 쿼럼(quorum)을 유지하고 서비스가 안정적으로 운영됩니다. 5대 구성 시 최소 3대는 정상 작동해야 합니다.
디스크 관리 고려사항
- 각 노드의 디스크는 KMS의 Replicas 개수에 맞게 충분히 확보되어야 함
- 노드 수가 증가할수록 필요한 디스크 공간도 비례하여 증가
기술 지원
- KMS 정상 구동 안 될 경우, SaaS R&D 1본부 인력 지원 협조 요청 가능
- 구성 과정에서 발생하는 기술적 문제는 Cloud연구본부에 문의 가능